wegene數據轉23andme數據的嘗試
本來想試一下dna.land的,結果發型墻內上不了dna.land.........
試了下gedmatch,雖然,去掉了wegene所有的定制位點,但是結果還是和原來一樣,有1+%的非洲
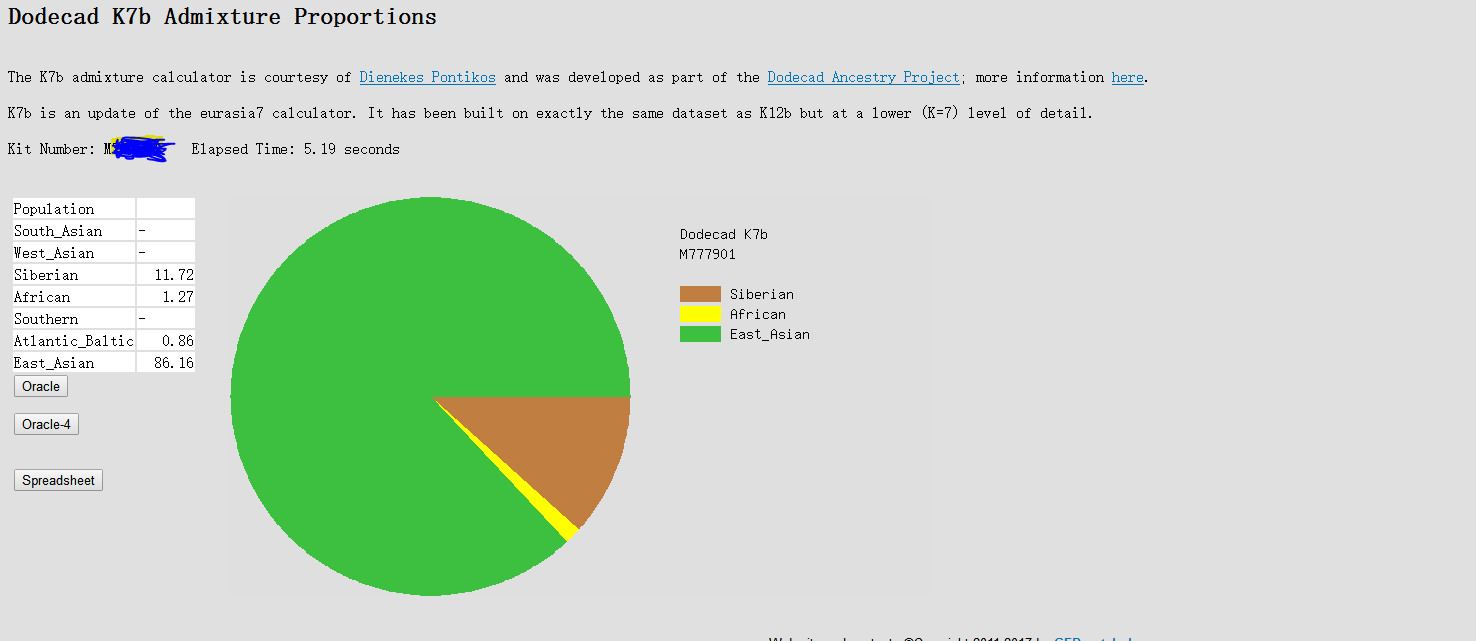
試了下gedmatch,雖然,去掉了wegene所有的定制位點,但是結果還是和原來一樣,有1+%的非洲


16 個回復
贊同來自:
贊同來自:
贊同來自:
贊同來自:
贊同來自: 費力科思
贊同來自: 藍星旗
?
把WeGene的原始數據轉換成23andme的數據,要解決的問題:
1. 23andme的數據是有5個版本的,從V1到V5。V5是剛剛出來,很多第三方也不支持,V4用了很多年,用得比較多。現在建議以V4為轉化目標。
2. 修改rawdata的頭部注釋信息。很多第三方應用都會驗證原始數據txt文件頭部的注釋信息,這個肯定要改成跟23andme一樣的。
3. 修改數據中的SNP列表。WeGene跟23andme的rawdata是有區別的,把兩者重疊的部分全部保留。
4. 剩下的是23andme數據中有,而WeGene數據中沒有的位點。這部分有幾種處理方法,根據我自己的看法,從易到難羅列一下:
4.1 全部標為未檢出:這顯然是最簡單的,但是會損失很多信息,有些第三方應用也會提示數據的nocall rate太高。
4.2 全部用中國人的高頻基因型填充:根據千人基因組項目的SNP frequency信息,把中國人群的高頻基因型填充進去。這個方法也可以細化一點,比如根據CHB和CHS對南方和北方的數據做不同的處理。
4.3 先用WeGene原始數據中所有的位點,用千人的Chinese做參考數據集,對23andme多測的那些位點的結果做imputation,把impute中info值比較高的位點的impute結果填充進去,impute效果不好的點用未檢出填充。
?
從合理性來說,4.3是最好的
贊同來自: 種驍楠
贊同來自:
贊同來自:
贊同來自:
贊同來自: wls 、藍星旗 、李璐mlxy 、wanhuatong
贊同來自:
贊同來自:
要回復問題請先登錄或注冊